Notebook Preset Development Tool
The dasl_client Python library, published by DASL, includes tools to support preset development. These tools are intended for use within Databricks notebooks. This guide explains how to use them through examples and supporting explanations where needed.
1. Outline
The following are the key requirements for running the preset development tool:
# Assuming the dasl_client is installed.
from dasl_client.preset_development import *
# The in-development preset YAML.
yaml_string = """
...
# preset YAML contents
...
"""
# The input parameters configuring this development environment's input data.
ds_params = PreviewParameters(spark)
# The preset engine.
ps = PreviewEngine(spark, yaml_string, ds_params)
# Evaluate invocation with Unity Catalog location of DASL gold table schema.
ps.evaluate("gold_catalog.gold_schema")
The preset development tool can be broken up into 3 main components:
- Input parameters
- Preset engine
- Preset YAML
Each of these will be presented in detail within this document. However, a summary is provided here to provide a high-level context of each component.
The preset engine passes a DataFrame from operation to operation as defined in the preset YAML. The provided input parameters indicate to the preset engine where to fetch records from in order to create the initial DataFrame. Once the DataFrame has had all defined operations completed on it, the preset engine will then present the results.
ℹ️ Please note that the Databricks notebooks’ spark context needs to be passed in as a parameter to the preset development tool in order to function correctly.
2. Components
This section delves into the details of each main component of the preset development tool presented in Section 1.
2.1. Input parameters
Input parameters (named PreviewParameters in code) define where and how records should be read as input into the preset engine. Currently, the preset development tool provides 3 methods to source records for use as input. These are “input”, “autoloader” and “table” and are selected through the use of .from_input(), .from_autoloader(), and .from_table(), respectively. Specific configuration for each input method is presented with that input methods section.
2.1.1 Input
Input is regarded as the simplest method to provide records to the preset engine. At a minimum, it requires 2 parts. The first part is the schema of the data, which is made up of a StructType containing an array of StructField defining the field types in each record. The second part is the record data that conforms with the types defined in the schema. The following is an example of how to use this input method:
# The input's schema.
schema = StructType([
StructField('person_name', StringType(), True),
StructField('age', IntegerType(), True),
StructField('some_array_struct',
ArrayType(
StructType([
StructField('ic1', StringType(), True),
StructField('ic2', StringType(), True)
])
),
True),
StructField('some_mappable_severity', IntegerType(), True)
])
# The input's records adhering to the provided schema.
data = [
("Mikhail", 15, [{"ic1": "val11", "ic2": "val12"}], 1),
("Zaky", 13, [
{"ic1": "val21", "ic2": "val22"},
{"ic1": "val31", "ic2": "val32"}
], 2),
("Zoya", 8, [{"ic1": "val41", "ic2": "val42"}], 3)
]
# Configuration of the input parameters.
ds_params = PreviewParameters(spark) \
.from_input() \
.set_data_schema(schema) \
.set_data(data)
Configuration options:
set_data_schema(schema: StructType)- The input records’ detailed field types.set_data(data: Dict[str, Any])- The input record’s data that adheres to the provided schema.
2.1.2 Autoloader
Using the autoloader input method will mimic how records are provided to a DASL datasource within a Databricks job. It uses the autoloader options defined in the preset YAML, such as file format and schema hints. In order to use this input method, you only need to specify the location of the records to read. Unless overridden, autoloader configuration is fetched from the preset YAML itself. The following is an example of how to use this input method:
# Configuration of the input parameters.
ds_params = PreviewParameters(spark) \
.from_autoloader() \
.set_autoloader_location("s3://some/bucket/path/**")
Configuration options:
set_autoloader_location(location: str)- The at rest location of records to read as input.set_autoloader_temp_schema_location(path: str)- Autoloader uses a stream reader and thus needs a temporary location to store its schema. The schema files are deleted post run. (Default:"dbfs:/tmp/schemas")set_autoloader_format(file_format: str)- Overrides the preset YAML’s autoloader file format.set_autoloader_schema_file(path: str)- Overrides the preset YAML’s autoloader schema file path.set_autoloader_cloudfiles_schema_hint_file(path: str)- Overrides the preset YAML’s schema hint file path.set_autoloader_cloudfiles_schema_hints(cloudfiles_schema_hints: str)- Overrides the preset YAML’s defined schema hints.set_autoloader_reader_case_sensitive(b: bool)- Sets whether the autoloader is case-sensitive when reading input field names. (Default:"true")set_autoloader_multiline(b: bool)- Sets whether the autoloader expects multiline JSON records. (Default:"true")
2.1.3 Table
You are also able to ingest records directly from a Unity Catalog table. An example use of this input method would be to process records already in a bronze table, or read records from a Databricks system table. When this input mode is used, field type information is collected from the target input table itself. The following is an example of how to use this input method:
# Configuration of the input parameters.
ds_params = PreviewParameters(spark) \
.from_table() \
.set_table("system.access.audit")
Configuration options:
set_table(unity_catalog_table_name: str)- The fully qualified unity catalog table name to read records from as input.
2.1.4 Shared configuration options
In addition to the configuration options specific to each input method, the following options are available for all input methods:
set_pretransform_name(pretransform_name: str)- Set the pretransform to use, by name, in the preset YAML. All transform stages will receive their input from the output of this pretransform.set_date_range(column: str, start_time: str, end_time: str)- Filter input records on the provided data range targeting the specified column.set_input_record_limit(record_limit: int)- Limit the number of input records read. (Default:10)
2.2. Preset YAML
Presets in DASL are defined in YAML and preset content in development with this tool are referred to as the “preset YAML” in this document. A preset needs to define the following components:
name- The preset’s name.author- The preset’s author.description- A concise description of the preset.autoloader- Autoloader configuration to use with this preset includingformat,schemaFile,cloudFiles.schemaHintsFileandcloudFiles.schemaHints.silver- The preset’s silver stages. This includes both the pretransform and transform stages.gold- The preset’s gold stage.
The silver pretransform, silver transform, and gold stages all have the same operations available to them. These operations are:
filter- Filters input records to the stage before processing any other stage operations.postFilter- Filters records that are outputted from the stage.fields- These are operations performed on records’ fields in the input DataFrame.namedefines the operation result’s output field name. One other field specification is used to define the operation to perform.name- The target field’s name.literal- Write the literal string value found here.from- Extract the value from this field name in the input DataFrame.expr- Perform the Spark SQL expression provided here.alias- Used to copy an output of any otherfieldsoperation. Thealiasprovided is the targetnameto copy.aliasoperations cannot reference otheraliasoperations.join- In summary, this operation is used to join the input DataFrame with an external table. Must result in a single field output.assert- Does not requirename. Checks the output record passes the provided defined assertion. Must result in boolean.
utils- These are utility functions that act outside of normal operations. A summary of the purpose of each utility function is provided.unreferencedColumns- This is used to carry forward columns unreferenced by a stage’sfromoperations to the next stage.jsonExtract- JSON extract occurs afterfilter, but beforefieldsoperations and when used will add fields found in the target JSON serialised string field to the input DataFrame.temporaryFields- Is used to provide additional fields to the input DataFrame that will not be carried forward as output from the implementing stage unless targeted specifically by afieldsoperation.unreferencedColumnsalso ignores these fields. The operations listed here occur 1 at a time, in order presented, thus making these operations chainable.
The following preset YAML template serves as a starting point for further development:
name: template_name
author: Antimatter
description: "Template description"
autoloader:
format: json
cloudFiles:
schemaHints: "unmapped VARIANT"
silver:
preTransform:
- name: template_pretransform_name
filter: ""
postFilter: ""
fields:
- name: "template_unmapped"
from: "unmapped"
- name: "template_literal"
literal: "template_literal"
- name: "template_alias"
alias: "template_literal"
- name: "time"
expr: "CAST(current_timestamp() AS string)"
utils:
unreferencedColumns:
preserve: true
transform:
- name: template_transform_name
filter: "2 = 2"
postFilter: "1 = 1"
fields:
- name: "time"
expr: "to_timestamp(time)"
- name: "referenced_temporary_field"
from: "temporary_template_literal"
utils:
unreferencedColumns:
preserve: true
temporaryFields:
- name: "temporary_template_literal"
literal: "temporary_value"
- name: "temporary_template_literal_to_forget"
literal: "another_temporary_value"
gold:
- name: target_gold_table_name
input: template_transform_name
filter: ""
postFilter: ""
fields:
- name: "time"
from: "time"
While a complete data source must define all stages, the preset development tool is designed to support partial configurations during development. For example, if you’re working on the silver transform stage, you don’t need to define the gold stage. The tool will evaluate the preset up to the last stage provided. The only requirement is that any referenced stages, such as a transform depending on a pretransform, must be defined.
2.3 Preset engine
This is the workhorse component of this tool. It takes the preset YAML and input parameters, then evaluates the preset according to the provided configuration.
2.3.1 Evaluation
To run the preset engine, you must provide the schema location of your DASL gold tables. This is required as one function of the preset engine is to evaluate whether the output from the preset YAML’s gold stage is compatible with the gold table targeted by that gold stage. Note that it doesn’t insert any data into these gold tables, they are just used as a schema reference. An example of invocation of the preset engine is below:
# Create the preset engine.
ps = PreviewEngine(spark, yaml_string, ds_params)
# Evaluate the provided YAML with input parameters, comparing any gold stage
# outputs to their gold stage tables found in the
# "databricks_dev.user_gold" schema.
ps.evaluate("databricks_dev.user_gold")
This is all that is required to run the preset engine. Output from the engine is presented in detail in Section 2.3.3.
2.3.2 Order of operations
The preset engine emulates a datasource as closely as possible. This means that operations need to be processed in the same order as a datasource. This order is as follows:
filterutils'stemporaryFieldsutils'sjsonExtractfields'sliteral,fromandexproperationsfields'sjoinoperationsfields'saliasoperationsfields'sassertoperationsutils'sunreferencedColumnspostFilter
2.3.3 Output
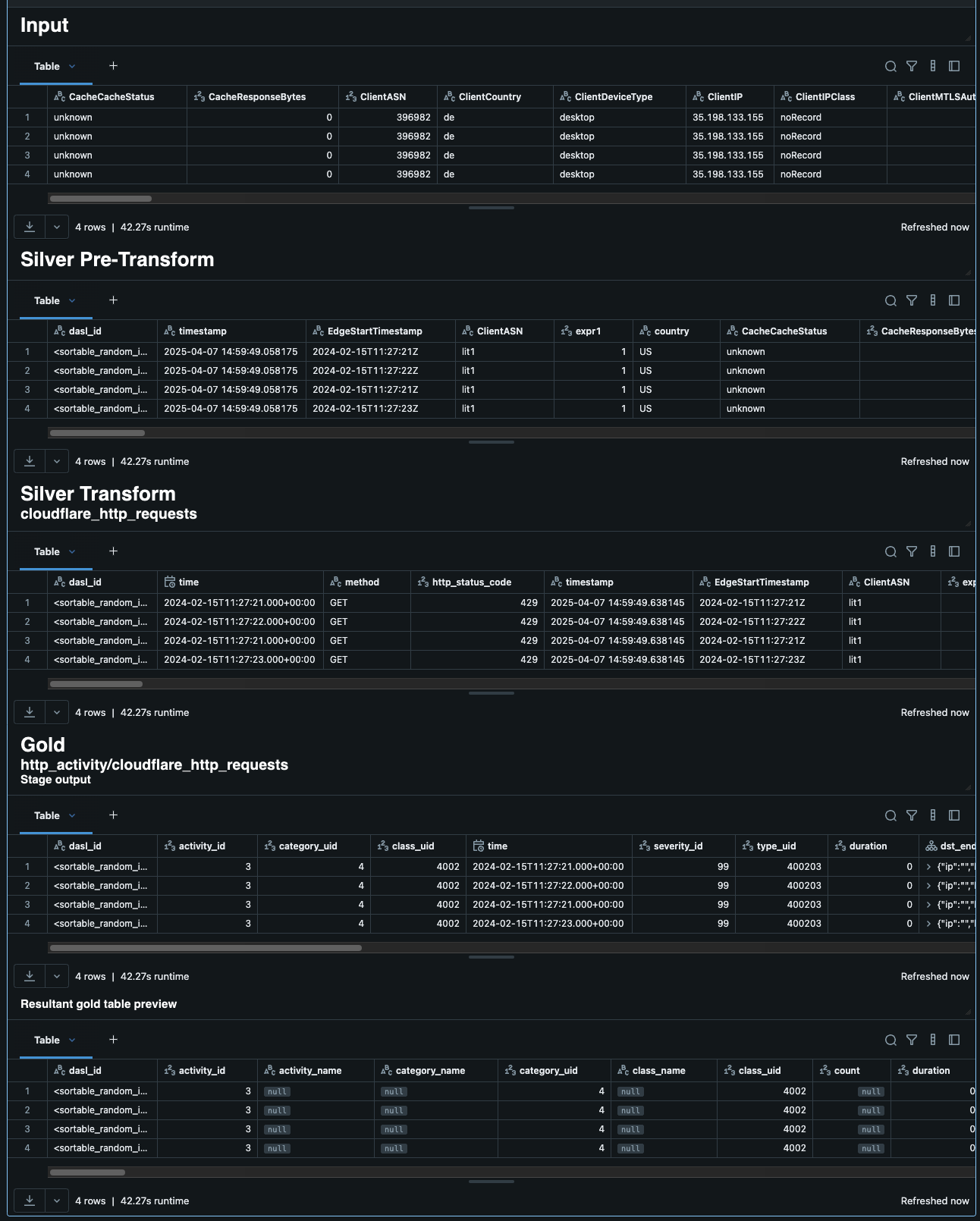
To aid in development, output for each stage evaluated is provided using Databricks’s built in display function. Included is the output for what was read in as input (as defined by the input parameters) before use by the first stage evaluated in the preset YAML.
All gold stages display 2 output tables. The first table is named the “Stage output”. This represents the records as they are when output from the gold stage. The second is the “Resultant gold table preview” which represents what the records will look like once written to the stage’s target gold table. A screenshot of the a successful evaluation is shown here:
3. Examples usage
3.1 Table mode transform only
This example preset takes input from the Databricks system.access.audit table and demonstrates several operations, including how to access struct fields and construct new struct values.
# Check can load from table input with no preset.
from dasl_client.preset_development import *
yaml_string = """
name: table_mode_skip
author: Antimatter
description: "This preset demos some operations, skips pretransform and has no gold stage."
silver:
transform:
- name: t_test_input_mode
fields:
# A literal.
- name: status
literal: info
# From primitive.
- name: audit_level
from: audit_level
# From structure.
- name: response_code
from: response.status_code
# Make a structure. Note dot notation.
- name: meta.version
from: version
- name: meta.workspace_id
from: workspace_id
- name: meta.agaent
from: user_agent
# Expression.
- name: unknown_agent
expr: CASE WHEN user_agent LIKE 'unknown%' THEN 'yes' ELSE 'no' END
"""
ds_params = PreviewParameters(spark) \
.from_table() \
.set_table("system.access.audit") \
.set_input_record_limit(5)
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.2 Input mode with assert
Presented below is an example preset YAML that will fail the age assertion. You can modify Zoya’s age to pass the assertion.
from dasl_client.preset_development import *
yaml_string = """
name: input_mode_assertion
author: Antimatter
description: "Simple input from input with asserts."
silver:
preTransform:
- name: pt_input_mode
utils:
unreferencedColumns:
preserve: true
transform:
- name: t_input_mode
fields:
- assert:
- expr: "1 = 1"
message: "Expected 1 to be equal to 1."
- expr: "age > 10"
message: "Expected age older than 10."
utils:
unreferencedColumns:
preserve: true
gold:
- name: http_activity
input: t_input_mode
fields:
- name: time
expr: current_timestamp()
"""
schema = StructType([
StructField('person_name', StringType(), True),
StructField('age', IntegerType(), True)
])
data = [
("Mikhail", 15),
("Zaky", 13),
("Zoya", 8)
]
ds_params = PreviewParameters(spark) \
.from_input() \
.set_data_schema(schema) \
.set_data(data) \
.set_pretransform_name("pt_input_mode")
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.3 Example autoload
An excerpt from an example preset YAML that makes advanced used of schema hints:
from dasl_client.preset_development import *
yaml_string = """
name: autoloader_mode
author: Antimatter
description: "A detailed schema hints example."
autoloader:
format: parquet
cloudFiles:
schemaHints: "text_name STRING,number_name INT,variant_name VARIANT,simple_struct_name struct<text:STRING,num:BIGINT>,embedded_struct_name struct<text:STRING,num:INT,embedded_struct:struct<text:STRING,bool:BOOLEAN>>,array_name array<INT>, struct_array_name array<struct<text:STRING,num:FLOAT>>"
...
# REST OF PRESET YAML
...
"""
ds_params = PreviewParameters(spark) \
.from_autoloader() \
.set_autoloader_location("s3://path/to/records/**") \
.set_pretransform_name("pretransform_stage_name")
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.4 Example with table and CSV joins
This example preset demonstrates both supported join operations: joining against an existing table in the Unity Catalog and joining with a CSV file stored in the Unity Catalog.
The table sev_map holds the following records:
| id | name |
|---|---|
| 0 | val0 |
| 1 | val1 |
| 2 | val2 |
| 3 | val3 |
| 4 | val4 |
| 5 | val5 |
| 6 | val6 |
| 7 | val7 |
| 99 | unk |
The contents of sev_map.csv are shown below:
id,name
0,v1
1,v2
2,v3
3,v4
4,v5
5,v6
6,v7
7,v8
99,u99
The preset YAML is as follows:
# Joins.
from dasl_client.preset_development import *
yaml_string = """
name: test_input_mode_joins
author: Antimatter
description: "An example of join operations."
silver:
transform:
- name: t_test_input_mode
fields:
- name: age
from: age
- name: "table_severity_joined"
join:
lhs: "some_mappable_severity"
rhs: "id"
select: "CONCAT(name, ' & more expression')"
withTable: "catalog.schema.sev_map"
- name: "csv_severity_joined"
join:
lhs: "some_mappable_severity"
rhs: "id"
select: "name"
withCSV:
path: "/Volumes/path/to/csv/sev_map.csv"
"""
schema = StructType([
StructField('person_name', StringType(), True),
StructField('age', IntegerType(), True),
StructField('some_mappable_severity', IntegerType(), True)
])
data = [
("Mikhail", 15, 1),
("Zaky", 13, 2),
("Zoya", 8, 3)
]
ds_params = PreviewParameters(spark) \
.from_input() \
.set_data_schema(schema) \
.set_data(data)
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.5 JSON extract
JSON extract is used in 2 output modes. The first outputs each top level field in the JSON string to a new field in the DataFrame. The second is accessed when embedColumn is set. In this mode, the JSON string is deserialised into a struct in the DataFrame using the field name provided in the embedColumn.
# JSON extract.
from dasl_client.preset_development import *
yaml_string = """
name: test_input_mode_json_extract
author: Antimatter
description: "Example JSON extract usage."
silver:
transform:
- name: t_test_input_mode
utils:
unreferencedColumns:
preserve: true
jsonExtract:
- source: "some_json"
- source: "some_json"
embedColumn: "json_embed"
omitFields: "city"
"""
schema = StructType([
StructField('person_name', StringType(), True),
StructField('age', IntegerType(), True),
StructField('some_json', StringType(), True)
])
data = [
("Mikhail", 15, '{"city": "Dreamtown", "country": "Sandland"}'),
("Zaky", 13, '{"city": "Cake City", "country": "Candy Steps"}'),
("Zoya", 8, '{"city": "Science Village", "country": "Smartopia"}')
]
ds_params = PreviewParameters(spark) \
.from_input() \
.set_data_schema(schema) \
.set_data(data)
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.6 Temporary fields
Temporary fields are only available in the stage they are introduced to even if unreferencedColumns is set to preserve all. In this example, one temporary field is carried into the transform stage using a from operation.
# Temporary fields.
from dasl_client.preset_development import *
yaml_string = """
name: template_name
author: Antimatter
description: "Template description"
silver:
preTransform:
- name: template_pretransform_name
fields:
- name: "referenced_temp_value"
from: "temporary_template_literal"
- name: "time"
expr: "CAST(current_timestamp() AS string)"
utils:
unreferencedColumns:
preserve: true
temporaryFields:
- name: "temporary_template_literal"
literal: "temporary_value"
- name: "temporary_template_literal_to_forget"
literal: "another_temporary_value"
transform:
- name: template_transform_name
fields:
- name: "time"
expr: "to_timestamp(time)"
utils:
unreferencedColumns:
preserve: true
gold:
- name: http_activity
input: template_transform_name
fields:
- name: "time"
from: "time"
"""
schema = StructType([
StructField('record_id', IntegerType(), True)
])
data = [
(1),
(2),
(3)
]
ds_params = PreviewParameters(spark) \
.from_input() \
.set_data_schema(schema) \
.set_data(data) \
.set_pretransform_name("template_pretransform_name")
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")
3.7 A DASL content pack sourced preset
This is a preset for ingesting AWS WAF logs targeting the http_activity gold table showing what a complete datasource might look like, and allowing this tool to show its feature set at work.
from dasl_client.preset_development import *
yaml_string = """
name: aws_sec_lake_waf_v2
author: Antimatter
description: "A preset for consuming logs generated by AWS WAFv1 logs"
autoloader:
format: json
cloudFiles:
schemaHints: "action string,formatVersion bigint,httpRequest struct<args:string,clientIp:string,country:string,headers:array<struct<name:string,value:string>>,httpMethod:string,httpVersion:string,requestId:string,uri:string>,httpSourceId string,httpSourceName string,nonTerminatingMatchingRules array<string>,rateBasedRuleList array<struct<rateBasedRuleId:string,rateBasedRuleName:string,limitKey:string,maxRateAllowed:int,evaluationWindowSec:string,customValues:array<struct<key:string,name:string,value:string>>>>,requestHeadersInserted string,responseCodeSent int,ruleGroupList array<struct<customerConfig:string,excludedRules:string,nonTerminatingMatchingRules:array<string>,ruleGroupId:string,terminatingRule:struct<ruleId:string,action:string,ruleMatchDetails:array<struct<conditionType:string,sensitivityLevel:string,location:string,matchedData:array<string>>>>>>,terminatingRuleId string,terminatingRuleMatchDetails array<string>,terminatingRuleType string,timestamp timestamp,webaclId string,requestBodySize int,requestBodySizeInspectedByWAF int,labels array<struct<name:string>>,oversizeFields array<string>,ja3Fingerprint string,captchaResponse struct<responseCode:int,solveTimestamp:timestamp,failureReason:string>"
silver:
transform:
- name: aws_wafv1_http_activity_2
fields:
- name: ocsf_activity_id
expr: CASE WHEN LOWER(httpRequest.httpMethod) = 'connect' THEN 1 WHEN LOWER(httpRequest.httpMethod) = 'delete' THEN 2 WHEN LOWER(httpRequest.httpMethod) = 'get' THEN 3 WHEN LOWER(httpRequest.httpMethod) = 'head' THEN 4 WHEN LOWER(httpRequest.httpMethod) = 'options' THEN 5 WHEN LOWER(httpRequest.httpMethod) = 'post' THEN 6 WHEN LOWER(httpRequest.httpMethod) = 'put' THEN 7 WHEN LOWER(httpRequest.httpMethod) = 'trace' THEN 8 WHEN httpRequest.httpMethod IS NULL OR httpRequest.httpMethod = '' THEN 0 ELSE 99 END
- name: ocsf_activity_name
expr: CASE WHEN httpRequest.httpMethod IS NULL OR httpRequest.httpMethod = '' THEN 'Unknown' ELSE CONCAT(UPPER(SUBSTRING(httpRequest.httpMethod, 1, 1)), LOWER(SUBSTRING(httpRequest.httpMethod, 2))) END
- name: ocsf_category_uid
expr: CAST('4' AS INT)
- name: ocsf_category_name
literal: Network Activity
- name: ocsf_class_uid
expr: CAST('4002' AS INT)
- name: ocsf_class_name
literal: HTTP Activity
- name: ocsf_severity_id
expr: CAST('99' AS INT)
- name: ocsf_severity
literal: Other
- name: ocsf_type_uid
expr: CAST(400200 + (CASE WHEN LOWER(httpRequest.httpMethod) = 'connect' THEN 1 WHEN LOWER(httpRequest.httpMethod) = 'delete' THEN 2 WHEN LOWER(httpRequest.httpMethod) = 'get' THEN 3 WHEN LOWER(httpRequest.httpMethod) = 'head' THEN 4 WHEN LOWER(httpRequest.httpMethod) = 'options' THEN 5 WHEN LOWER(httpRequest.httpMethod) = 'post' THEN 6 WHEN LOWER(httpRequest.httpMethod) = 'put' THEN 7 WHEN LOWER(httpRequest.httpMethod) = 'trace' THEN 8 WHEN httpRequest.httpMethod IS NULL OR httpRequest.httpMethod = '' THEN 0 ELSE 99 END) AS BIGINT)
- name: ocsf_type_name
expr: "CONCAT('HTTP Activity: ', httpRequest.httpMethod)"
- name: time
from: timestamp
- name: action
expr: CASE WHEN action = 'ALLOW' THEN 'Allowed' WHEN action = 'BLOCK' then 'Denied' ELSE 'Unknown' END
- name: action_id
expr: CASE WHEN action = 'ALLOW' THEN 1 WHEN action = 'BLOCK' then 2 ELSE 0 END
- name: log_action
from: action
- name: ocsf_metadata.uid
from: httpRequest.requestId
- name: ocsf_metadata.product.name
literal: "WAFv2"
- name: ocsf_metadata.log_version
expr: CAST(formatVersion AS string)
- name: ocsf_metadata.log_provider
from: webaclId
- name: ocsf_metadata.logged_time
from: timestamp
- name: ocsf_metadata.tags
from: labels
- name: ocsf_http_request.body_length
from: requestBodySize
- name: ocsf_http_request.http_method
from: httpRequest.httpMethod
- name: ocsf_http_request.args
from: httpRequest.args
- name: ocsf_http_request.version
from: httpRequest.httpVersion
- name: ocsf_http_request.url.url_string
from: httpRequest.uri
- name: ocsf_http_request.http_headers
from: httpRequest.headers
- name: ocsf_http_request.user_agent
expr: CASE WHEN SIZE(filter(httpRequest.headers, x -> x.name = 'User-Agent')) = 1 THEN element_at(filter(httpRequest.headers, x -> x.name = 'User-Agent'), 1).value ELSE null END
- name: ocsf_http_response.code
from: responseCodeSent
- name: ocsf_src_endpoint.ip
from: httpRequest.clientIp
- name: ocsf_src_endpoint.location.country
from: httpRequest.country
- name: ocsf_tls.certificate.fingerprints
expr: ARRAY(named_struct('value', ja3Fingerprint))
- name: rate_limit
from: rateBasedRule.maxRateAllowed
- name: rate_based_rule_id
from: rateBasedRule.rateBasedRuleId
- name: rate_based_rule_keys
expr: CASE WHEN rateBasedRule.limitKey = 'CUSTOMKEYS' THEN transform(rateBasedRule.customValues, x -> CONCAT(x.key, ':', x.name, ':', x.value)) ELSE ARRAY() END
- name: rate_based_rule_location
expr: concat_ws(',', array_distinct(rateBasedRule.customValues.key))
- name: terminatingRuleType
from: terminatingRuleType
- name: nonTerminatingMatchingRule
from: nonTerminatingMatchingRule
- name: disposition
expr: CASE WHEN action = 'ALLOW' THEN 'Allowed' WHEN action = 'BLOCK' then 'Blocked' ELSE 'Unknown' END
- name: disposition_id
expr: CASE WHEN action = 'ALLOW' THEN 1 WHEN action = 'BLOCK' then 2 ELSE 0 END
- name: ocsf_observables
expr: "ARRAY(
named_struct('name', 'oversizeFields', 'type_id', 99, 'type', 'Other', 'value', to_json(oversizeFields)),
named_struct('name', 'httpSourceId', 'type_id', 10, 'type', 'Resource UID', 'value', httpSourceId),
named_struct('name', 'httpSourceName', 'type_id', 1, 'type', 'Hostname', 'value', httpSourceName)
)"
- name: firewall_rule_condition
expr: CASE WHEN log_action = 'BLOCK' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN term_conditionType WHEN log_action = 'ALLOW' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN nonTerm_conditionType ELSE null END
- name: firewall_rule_match_location
expr: CASE WHEN log_action = 'BLOCK' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN term_location WHEN log_action = 'ALLOW' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN nonTerm_location WHEN terminatingRuleType = 'RATE_BASED' THEN rate_based_rule_location ELSE null END
- name: firewall_rule_match_details
expr: CASE WHEN log_action = 'BLOCK' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN term_matchedData WHEN log_action = 'ALLOW' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN nonTerm_matchedData WHEN terminatingRuleType = 'RATE_BASED' THEN rate_based_rule_keys ELSE null END
- name: firewall_rule_sensitivity
expr: CASE WHEN log_action = 'BLOCK' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN term_sensitivityLevel WHEN log_action = 'ALLOW' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN nonTerm_sensitivityLevel ELSE null END
- name: firewall_rule_uid
expr: CASE WHEN log_action = 'BLOCK' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN terminatingRuleId WHEN log_action = 'ALLOW' AND (terminatingRuleType = 'REGULAR' OR terminatingRuleType = 'GROUP') THEN nonTerminatingMatchingRule.ruleId WHEN terminatingRuleType = 'RATE_BASED' THEN rate_based_rule_id ELSE null END
- name: firewall_rule_rate_limit
expr: CASE WHEN terminatingRuleType = 'RATE_BASED' THEN rate_limit ELSE null END
- name: ocsf_unmapped
expr: to_json(named_struct('ruleGroupList', ruleGroupList, 'rateBasedRuleList', rateBasedRuleList, 'captchaResponse', captchaResponse))
utils:
temporaryFields:
- name: nonTerminatingMatchingRule
expr: explode_outer(transform(nonTerminatingMatchingRules, x -> from_json(x, 'struct<ruleId:string,action:string,ruleMatchDetails:array<struct<conditionType:string,location:string,matchedData:array<string>,matchedFieldName:string,sensitivityLevel:string>>>')))
- name: rateBasedRule
expr: explode_outer(rateBasedRuleList)
- name: terminatingMatchRuleDetails
expr: explode_outer(transform(terminatingRuleMatchDetails, x -> from_json(x, 'struct<conditionType:string,location:string,matchedData:array<string>,matchedFieldName:string,sensitivityLevel:string>')))
- name: nonTerminatingMatchingRuleDetails
expr: explode_outer(nonTerminatingMatchingRule.ruleMatchDetails)
- name: nonTerm_conditionType
alias: nonTerminatingMatchingRuleDetails.conditionType
- name: nonTerm_location
alias: nonTerminatingMatchingRuleDetails.location
- name: nonTerm_matchedData
alias: nonTerminatingMatchingRuleDetails.matchedData
- name: nonTerm_matchedFieldName
alias: nonTerminatingMatchingRuleDetails.matchedFieldName
- name: nonTerm_sensitivityLevel
alias: nonTerminatingMatchingRuleDetails.sensitivityLevel
- name: term_conditionType
alias: terminatingMatchRuleDetails.conditionType
- name: term_location
alias: terminatingMatchRuleDetails.location
- name: term_matchedData
alias: terminatingMatchRuleDetails.matchedData
- name: term_matchedFieldName
alias: terminatingMatchRuleDetails.matchedFieldName
- name: term_sensitivityLevel
alias: terminatingMatchRuleDetails.sensitivityLevel
unreferencedColumns:
preserve: true
gold:
- name: http_activity
input: aws_wafv1_http_activity_2
fields:
- name: activity_id
from: ocsf_activity_id
- name: activity_name
from: ocsf_activity_name
- name: category_uid
from: ocsf_category_uid
- name: category_name
from: ocsf_category_name
- name: class_uid
from: ocsf_class_uid
- name: class_name
from: ocsf_class_name
- name: severity_id
from: ocsf_severity_id
- name: severity
from: ocsf_severity
- name: type_uid
from: ocsf_type_uid
- name: type_name
from: ocsf_type_name
- name: time
from: time
- name: action
from: action
- name: action_id
from: action_id
- name: disposition
from: disposition
- name: disposition_id
from: disposition_id
- name: metadata
from: ocsf_metadata
- name: http_request
from: ocsf_http_request
- name: http_response
from: ocsf_http_response
- name: src_endpoint
from: ocsf_src_endpoint
- name: observables
from: ocsf_observables
- name: firewall_rule.condition
from: firewall_rule_condition
- name: firewall_rule.match_location
from: firewall_rule_match_location
- name: firewall_rule.match_details
from: firewall_rule_match_details
- name: firewall_rule.sensitivity
from: firewall_rule_sensitivity
- name: firewall_rule.uid
from: firewall_rule_uid
- name: firewall_rule.rate_limit
from: firewall_rule_rate_limit
- name: unmapped
expr: CAST(ocsf_unmapped AS VARIANT)
"""
ds_params = PreviewParameters(spark) \
.from_autoloader() \
.set_autoloader_location("s3://path/to/records/**") \
.set_input_record_limit(10)
ps = PreviewEngine(spark, yaml_string, ds_params)
ps.evaluate("gold_catalog.gold_schema")